News Centerbarrow
Industry News
NVIDIA to officially unveil Turing architecture: greatest leap in graphics since
2019-05-27 23:15 The author:Administrator
While NVIDIA officially announced a new generation of GeForce game card should have to wait until next week's game show in front of the cologne "GeForce Gaming Celebration" activities, but the SIGGRAPH 2018, officially opened yesterday, the graphics community top meeting, NVIDIA is impossible to come empty-handed, but they do have many heavyweight released last night, including new Turing architecture (note that the official Po now also did not use any Chinese name), including the first special light track GPU: Quadro RTX, but let's start with its roots: the new Turing architecture.

NVIDIA's official live is 8:45 this morning about the end of the, now there are many details not released, so let's take a look at the official Newsroom, first on Turing architecture, NVIDIA to its very confident, as since 2006, through a unified rendering architecture brings the greatest leap after CUDA, so you can imagine the NVIDIA expects of its, or ambitions. New Turing architecture it is important of mixed Rendering (Hybrid Rendering) to realize the ray tracing, specifically including the introduction of new RT Core to accelerate ray tracing, and we have seen in Volta structure Tensor Core to speed up the AI, and of course the rasterizer, after all, now we have not severe enough to abandon the extent of the rasterizer, so the new Turing architecture is contains a variety of forces, which contains various power to realize the ray tracing Hybrid Rendering, should become the key word.
Every time a new architecture comes along, what we care most about is the change in the level of microarchitecture: what new features are added, what are the leaner parts. If the Volta architecture is starting to look at Tensor Unit, the most important part of the new Turing architecture is the newly introduced RT Core. Now that is "RT", just as its name implies is blunt Ray Tracing the Ray Tracing), its role is to accelerate the processing of the propagation of light in a three-dimensional environment, dealing with the speed of light is 25 times the Pascal architecture, at the same time let the GPU as a node to deal with the bottom Frame (Final Frame), the effect of rendering to 30 times faster than the speed of the CPU as node.

Exciting is at the same time, introduced since Volta structure Tensor Core, we all know that it can provide much higher than traditional artificial intelligence, deep learning performance of GPU, this part of the performance to be able to give us no GPU to do a lot of previous work, such as the Turing structure Tensor of the Core, able to handle 500 trillion Tensor operations per second, through this part of the performance, we can realize the function of the past can't entertain wild hope, such as new anti-aliasing technology based on deep learning: DLAA (Deep Learning anti-aliasing, everything is based on depth calculations).
Finally, in terms of traditional architectures, Turing added Integer Unit cells to the familiar SM cells, and the new uniform caching architecture, which brings twice the bandwidth of the current architecture. In terms of specs, the Turing architecture can carry up to 4608 CUDA and deliver up to 16 tflop floating point performance. This is, of course, the most powerful of the three new Quadro RTX graphics CARDS.

Specifically, NVIDIA last night released a total of three CARDS, respectively is Quadro RTX 5000\6000\8000, the top RTX with 8000 times the flagship RTX 6000 two graphics on the flow number of processors, number of tensor units, ray tracing performance are consistent, respectively is 4608 CUDA, 576 TC, 10 GigaRays, only memory vary, RTX is carrying 24 6000 gb GDDR6 memory, through NVLink bridge can realize 48 gb memory, As far as 16Gb of video memory is concerned, that's a stretch, and the RTX 8000 simply doubles. The "entry-level" RTX 5000 is 3072 CUDA, 384 TC (Tensor Cores), 6 GiagaRys, and 16GB GDDR6 memory.

On the flow processor side, if you follow the architecture of Volta V100, it is that each set of SM units contains 64 CUDA, or 72 sets of SM units, but how do 72 sets of SM units constitute a GPC unit? In the past, the Volta V100 used to contain 14 sets of SM units per GPC unit, so this is not the only way that NVIDIA has hidden redundant SM units. Since the GPC unit is definitely made up of 4 groups, 6 groups and 8 groups, if it is made up of 6 groups, it should be 6*14=84 groups of SM units. Even if it is made up of 128 CUDA/SM, either the composition of each group of GPC units has been simplified, or the current RTX 8000 is not complete architecture.

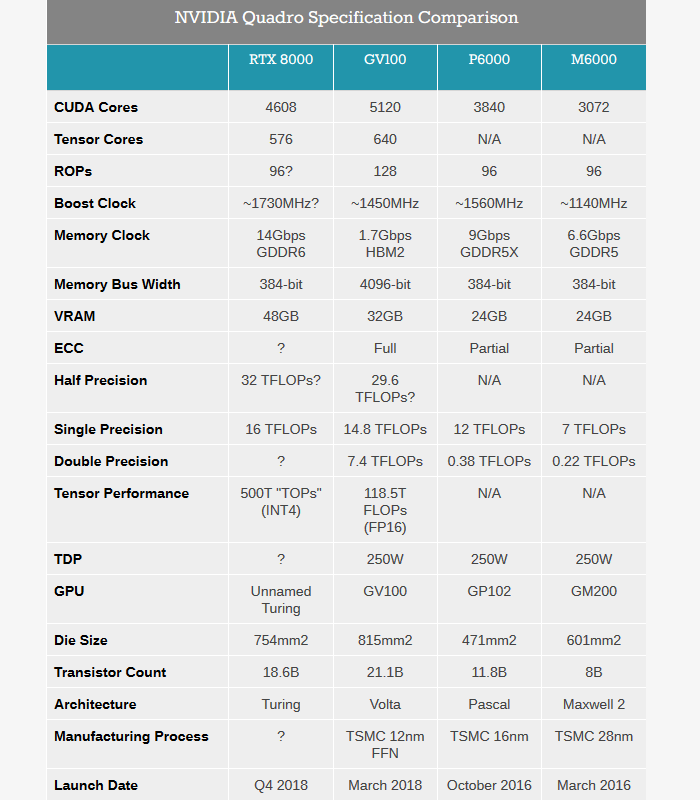
At least on the specifications of the card itself, the current AnandTech has got some news, the contrast between the they have made architecture, is RTX 8000 compared to 100, P6000, M6000 GV respectively, the first thing we can see in the core area, number of the transistor, CUDA, texture unit of the specifications of the terms of the number of contrast V100 is compact (even the core area of smaller), frequency to 1730 MHZ, 14 GBPS frequency of memory, a 384 - Bit wide, 16 single-precision TFlops, the core code is remains unclear, GT102? Now who knows.
news from:超能网

